
How Object Detection Evolved: From Region Proposals and Haar Cascades to Zero-Shot Techniques
Table Of Contents
- Introduction
- A Road Maps of Object Detection
- Traditional Detection Methods
- Deep Learning-based Detection Methods
- (Zero | One | Few) - Shot Object Detection
- Conclusion
The development of Object Detection algorithms has come a long way, starting with early computer vision and reaching a high level of accuracy through deep learning. In this post, we will look at the stages of development of these algorithms and the main methods used in modern object detection systems.
We start with a review of the early traditional object detection methods: Viola-Jones Detectors, HOG Detector, Part-based Approaches. They were actively used at the beginning of the development of this field.
Then, gradually move on to more modern deep learning object detection approaches based on Two-stage and One-stage Object Detection neural networks: RCNN, YOLO, SSD, CenterNet. These methods provide an end-to-end architecture that allows the algorithm to be adapted to any input data.
We end with the Zero-Shot object detection methods, which allow you to search for any objects in images without even training a neural network: OWL-ViT, GLIP, Segment Anything, GVT.
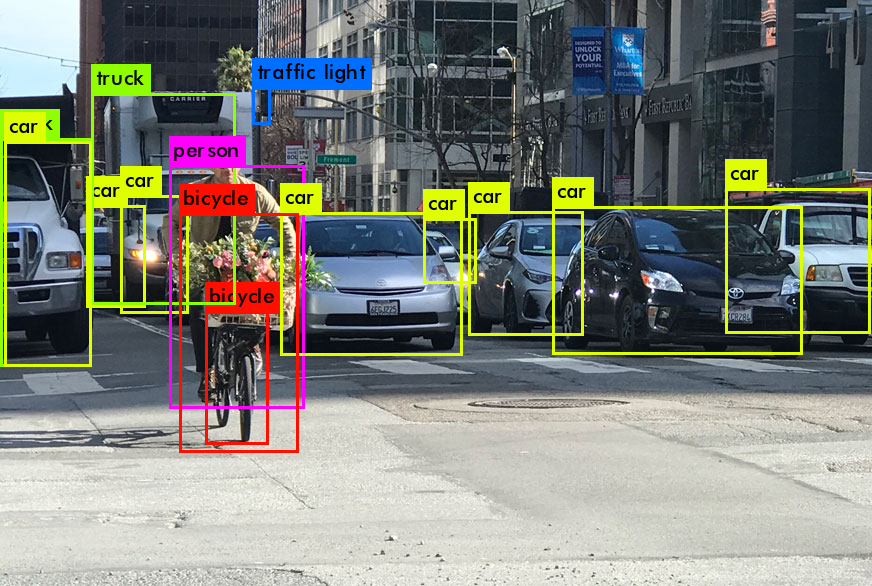
Introduction
In this article, we’ll look at the topic of Object Detection, what it means, what are its advantages for newcomers to the field, and why it’s interesting. Further discussion will be devoted to general roadmaps, where we will look at three or four important and interesting charts. We will also try to analyze the trends and evolution of Object Detection in general.
Let’s start with the basics. The Object Detection task can be formulated very simply: What objects are located where?
Object Detection is a crucial task in computer vision where the objective is to identify and locate various objects, like cars, cyclists, and traffic lights, within an image. This is achieved by defining rectangular regions using coordinates (xmin, ymin, xmax, ymax) and associating them with a classification and probability vector (p_1, p_2, ..., p_n). Object Detection surpasses image classification in practical significance as it enables the detection of objects for subsequent analysis, modification, or classification. Techniques like Stable Diffusion and Face Swap leverage object detection to manipulate and replace objects or faces in images. Challenges arise when multiple objects of the same class, such as pedestrians, overlap, prompting the use of Non-Maximum Suppression as a common solution, although alternative methods are emerging.
Object Detection is an extremely important task that has been developed and improved over the past ~30 years.
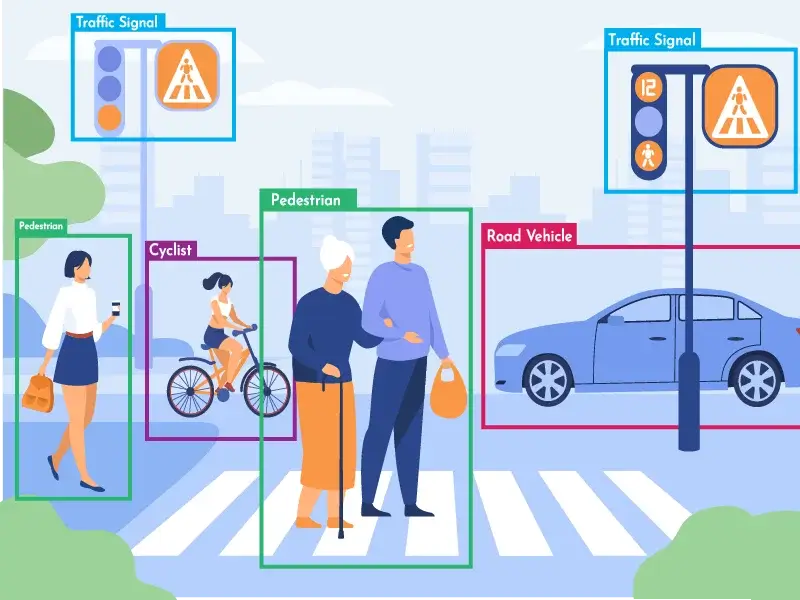
The development of Object Detection algorithms is an active area of research, and we continue to observe new trends and advances in this field.
Its applications are widespread in a variety of industries, from video surveillance and autonomous cars to medicine and retail, specifically:
- Video surveillance: detecting people and their location in video footage, monitoring the distance between them.
- Automotive industry: using computer vision to understand the environment and road safety.
- Medical diagnostics: detecting tumors and other abnormalities in images for analysis.
- Retail: automating the process of accounting for goods, detecting theft.
- Agriculture: monitoring plant health, disease detection, field analysis, and other agricultural tasks.
A Road Maps of Object Detection
Let’s start with the “roadmaps”. This section contains figures from some articles, which describe the develoment of the object detection methods. Let’s give an overview of these roadmaps, focusing on some important points.
Road Map (general)
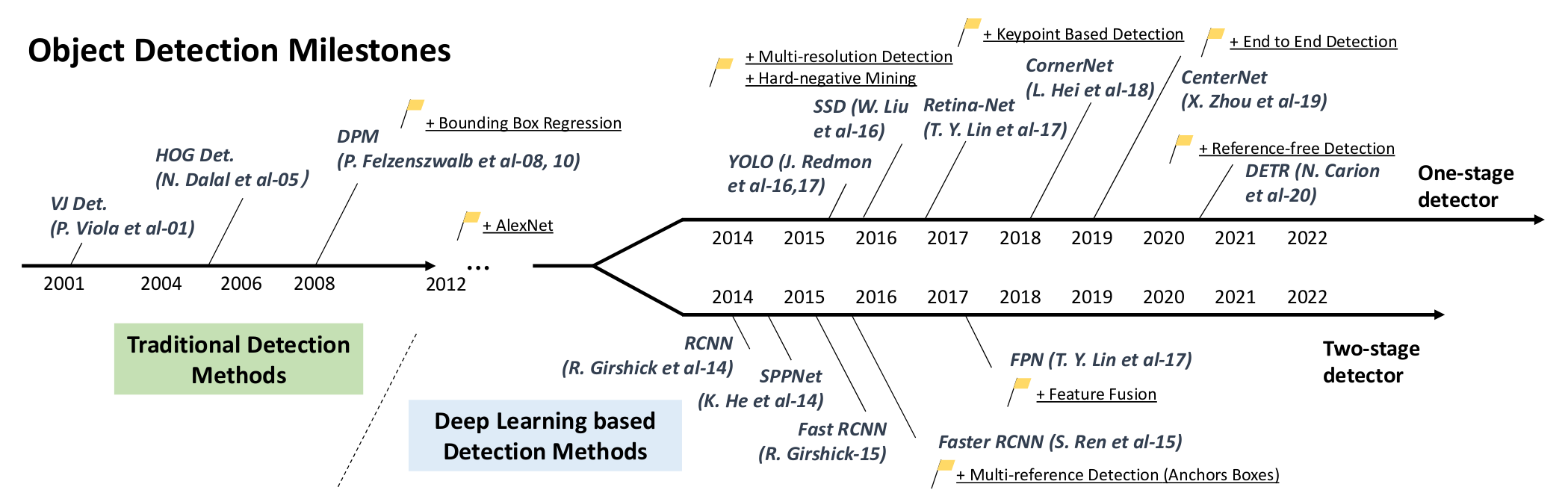
At the beginning of the diagram below, you can see that convolutional neural networks have been in development since the 1980s. In 1998, LeCun et al. introduced LeNet-5, a significant CNN architecture for digit recognition.
This dataset, known as MNIST, originated in the 90s and has since become a popular benchmark for evaluating machine learning and deep learning algorithms.
Later, there were requests for object detection, but at that time there were not enough effective methods for this.
The first significant method was the Viola-Jones or Haar cascade, which was fast and easy to use on the PCs of the time, providing an acceptable speed of several frames per second (FPS).
A few years later, the HOG Detector method was introduced as an alternative to Viola-Jones, primarily focusing on capturing object shapes and contours.
Later, methods using Deformable Parts Models (DPM) came into play, which for a long time occupied leading positions in object detection accuracy ratings.
In 2012, the first large deep neural networks appeared, including AlexNet. Although slow and computationally intensive, the architectures of AlexNet and subsequent models such as MobileNet became more optimal.
These models provided high-quality representative image features that can describe the context and detect a wide range of objects.
One of the most important aspects of these methods is their ‘end-to-end’ nature, where the input image undergoes a sequence of differentiated operations, enabling holistic processing within a single architecture.
Road Map (more traditional methods)
The development of the object detection has mainly been made through two historical periods: “traditional object detection period (pre-2014)” and “deep learning-based detection period (post-2014)”.
In the period before 2014, most object detection algorithms were built on the basis of manually created features. For example, in 2001, P. Viola and M. Jones achieved real-time human face detection without any constraints using the VJ detector. This detector used a “sliding window” technique that went through all possible locations and scales in an image to see if any window contained a human face.
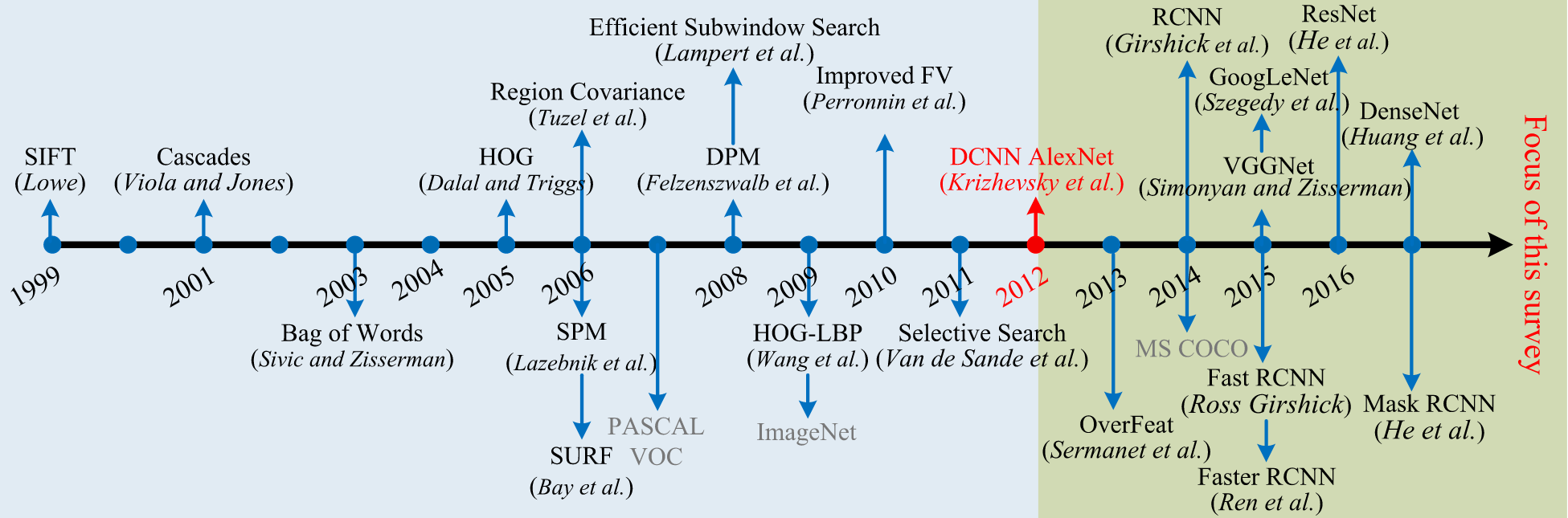
SIFT (Scale-Invariant Feature Transform) is a method used to extract and describe distinctive features from images. Using traditional computer vision methods, various functions and features describing an image can be calculated. For example, you can calculate the image gradient by taking the difference between pixel values of neighboring pixels. This is an important step in feature extraction. Additionally, the Laplacian operator can be applied to detect edges in an image. SIFT divides the image into keypoint neighborhoods or interest regions, from which features describing these regions can be extracted. By comparing these features with a descriptor representing the object, the most similar region to the object can be identified. This way, you can express a high probability that the object is located there.
At the simplest level, this means finding the most similar part of the image. What other traditional methods are there? To be honest, I didn’t really look into it because almost none of them are used anymore. The only thing that might still be used is Haar cascades, if you need fast face detection.
Road Map (deep learning methods)
In the period after 2014, with the advent of deep learning, object detection began to develop at an unprecedented pace. For example, in 2014, R. Girshick et al. proposed the Regions with CNN features (RCNN) method, which significantly improved the accuracy of object detection.
Continuing, in 2015, S. Ren et al. proposed the Faster RCNN detector, which was the first near-real-world detector based on deep learning. The main contribution of Faster-RCNN is the introduction of the Region Proposal Network (RPN), which allows to obtain region proposals almost for free. From R-CNN to Faster RCNN, most of the individual blocks of the object detection system, such as sentence detection, feature extraction, bounding box regression, etc., have been gradually integrated into a single final learning framework.
In 2017, T.-Y. Lin et al. proposed Feature Pyramid Networks (FPN). FPNs have shown significant progress in detecting objects with a wide range of scales. By using FPNs in the main Faster R-CNN system, it achieves the best results of detecting a single model on the COCO dataset without additional tuning.
As for single-stage detectors, YOLO (You Only Look Once) was proposed by R. Joseph et al. in 2015. YOLO is extremely fast: the fast version of YOLO runs at 155 frames per second. YOLO applies a single neural network to a complete image. This network divides the image into regions and simultaneously predicts bounding boxes and probabilities for each region.
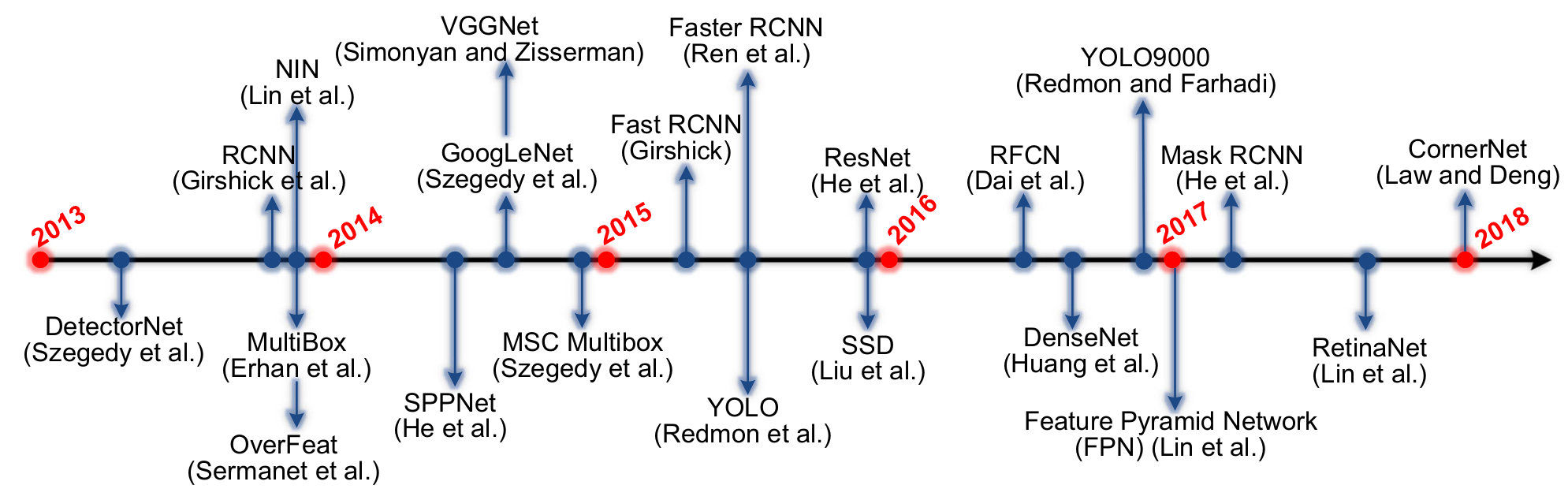
Object Detection Metrics Improvements
An important aspect when evaluating Object Detection algorithms is the mean Average Precision (mAP) metric. This metric measures the relationship between precision and recall of the algorithm when the threshold is changed. The use of confidence threshold in algorithms such as YOLOv5 allows you to discard predictions with low probability. It is important to find a balance between precision and recall, which is reflected in the mAP metric.
We analyze in details the development and improvement of object detection mAP on the VOC07, VOC12 and MS-COCO datasets.
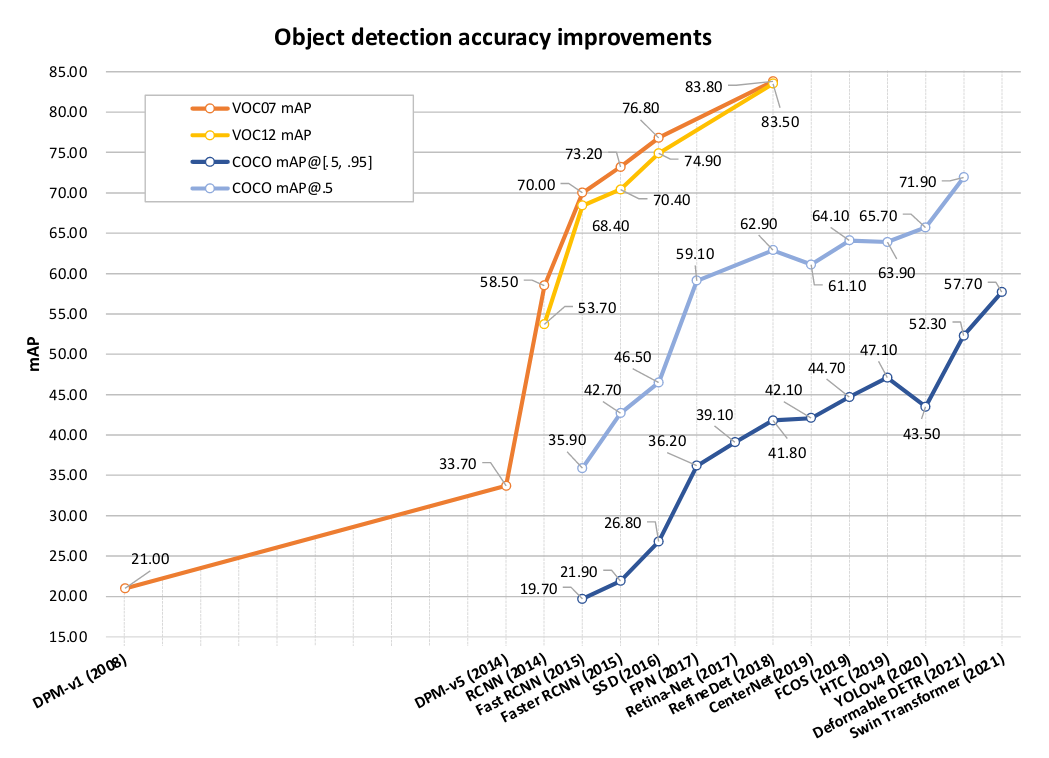
- On the VOC07 dataset, the mAP of object detection increased from 21% in 2008 (DPM method) to 83.8% in 2018 (RefineDet). +62.8%
- On the VOC12 dataset, the mAP increased from 53.7% in 2014 (R-CNN method) to 83.5% in 2018 (RefineDet). +29.8%
- On the MS-COCO dataset, the mAP of object detection increased from 19.7% in 2015 (Fast R-CNN method) to 57.7% in 2021 (Swin Transformer). +38%
These data confirm the significant progress in object detection in recent years, especially with the advent of deep learning and its application in object detection methods.
Traditional Detection Methods
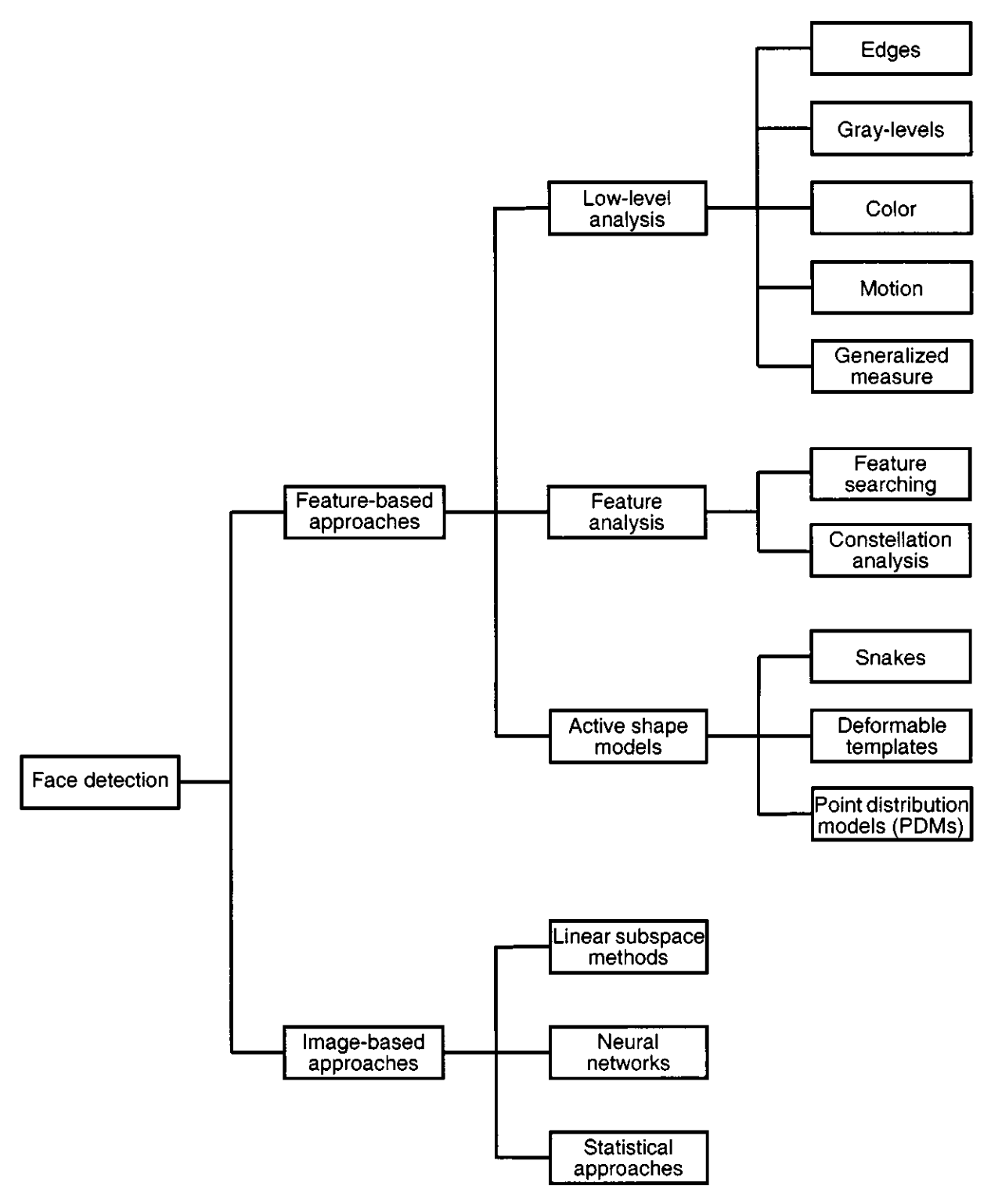
The world of object detection algorithms has seen many changes since the first time methods for face recognition were actively researched. In this article, we will look at the development of this field since 2001, when several reviews of object-based face detection methods have already been conducted.
At that time, there were two main approaches: Image-based and Feature-based. Image-based approaches used methods such as SVMs (Support Vector Machines) and Linear Subspace Methods. They also made use of convolutional neural networks (CNNs) like LeNet, which played a significant role in early image recognition tasks. Statistical methods were also employed, including techniques such as Gaussian mixture models and probabilistic models based on the normal distribution.
Although some of these methods were interesting from a research point of view and may have their value for general familiarization, they are no longer used much in modern object detection systems. Instead, modern approaches are based on large neural networks that allow for efficient image comparison and object recognition. Such approaches provide much more representative results.
Viola-Jones Detectors (2001)
One of these algorithms - the Haar cascade, also known as the Viola-Jones algorithm.

The Haar cascade algorithm is based on a simple idea. If we want to detect faces in an image, generally speaking, all faces have similar characteristics, such as two eyes, a nose, and a mouth. For example, the eyes usually have a certain shape, the bottom of the face is darker because of shadows, and the cheeks and nose can be highlighted when taking a photo.
Thus, we can form a set of templates that describe these face characteristics. These templates can be in the form of small squares or rectangles. Convolution operations are used to convolve these templates with image patches to generate feature maps, which are subsequently analyzed for object detection.
The cascade approach of the Haar algorithm is used because of its advantages. The authors use a boosting method and sequentially apply different templates, which allows detecting faces with a lot of variability, such as tilts and lighting conditions. After sequentially applying different classifiers based on the cascade of templates, the algorithm makes decisions at each stage to determine whether to continue evaluating a candidate region as a face or reject it.
As a result, we get an object detector that works quickly and can show good results when various factors, including training data, feature selection, and application context, are considered.
HOG Detector (2005)

The HOG (Histogram of Oriented Gradients) algorithm was invented in 2005 and differs from deep learning image processing methods by not using neural networks.
-
First, the image is divided into small subpictures of 8x8 pixels. For each subimage, gradients are calculated, resulting in a set of gradient values. These values are distributed into a histogram with a specified number of bins, representing the distribution of gradients in that subregion. The histograms from multiple subregions are concatenated to form the feature vector.
-
Next, the histograms are normalized using a process such as histogram equalization to enhance the contrast and equalize the intensity amplitude of pixels in different parts of the image. This helps improve the overall visual representation.
-
After normalizing the histograms, a descriptor is computed for each region covered by a sliding window that moves across the image at multiple scales and aspect ratios. By examining these detection windows and comparing the feature vectors extracted from them, objects like faces can be detected. A trained classifier, often a support vector machine (SVM), is used to determine whether the object of interest is present.
While this method can detect faces, it may not be as effective in detecting fine-grained details or complex structures such as scratches or brain tumors, limiting its use for such tasks.
At first glance, one might suggest incorporating more complex features that consider color and other parameters, and indeed, further research has explored such modifications. For instance, combining HOG with other feature descriptors like Histograms of Color or Haar-like features has shown promising results. Additionally, there exist effective methods that leverage partial features for object detection, such as combining multiple feature descriptors to find objects like a person or a face. Although these methods can be more intricate, they have demonstrated improved accuracy in certain scenarios.
Overall, the HOG method is an effective approach for detecting objects in images, particularly for tasks like face detection. By utilizing mathematical methods and gradient-based features, it achieves good results. Nevertheless, further research and modifications of the method can lead to improvements in its efficiency and accuracy.
Part-based Approaches
- Deformable Part-based Model (2010)
- Implicit Shape Model (2004)
The Deformable Part-based Model (DPBM), proposed by Felzenszwalb et al. in 2010, is an object detection method based on the concept of variable-shaped parts. The Implicit Shape Model (ISM), proposed by Leibe et al. in 2004, is an object detection method that represents the shape of an object as a set of local features and uses statistical methods to find the most likely areas of an object in an image. Both methods have been widely used in object detection tasks, helping to improve the accuracy and reliability of image processing algorithms.

Deep Learning-based Detection Methods
At the beginning of any deep learning-based object detection process, we have an input image that is fed to the model. This image can be processed in its original form or resized to a fixed size. Then, at each scale, we search for objects, and the results are averaged. There are different approaches to this task.

After processing an image or a set of images, they are transferred to the model backbone. The task of the backbone is to extract various features from the image, creating feature vectors that describe the image. There are many different backbone models, such as AlexNet, VGG, ResNet, YOLO (using a modified version of DarkNet as its backbone), EfficientNet, MobileNet, and DenseNet.
The obtained features are passed from the backbone to the intermediate layers responsible for feature refinement before passing them to the head. In some architectures, there may be no intermediate module between the backbone and the head, and the features are directly passed to the head for generating the final bounding boxes and class predictions. The overall goal is to determine the location and class of objects.
Two- and One- Stage Detectors

Object detection algorithms can be divided into two categories: two-stage and one-stage. In two-stage algorithms, the backbone and neck tasks involve creating regional proposals. Features are extracted from the image and transferred to a neural network that returns a set of potential object locations and their confidence. Alternatively, a selective search algorithm can be used to generate object proposals. The received features, along with the suggestions, are transferred to the subsequent stages/components of the algorithm for further processing.
In contrast, one-step algorithms use a simpler and faster approach. The image is processed directly, and features are extracted to detect objects without an explicit proposal generation step.
Two-Stage Detectors
RCNN (2014)
The first algorithm we will talk about is R-CNN (Region-based Convolutional Neural Network). It introduced the concept of region-based detection by employing a multi-stage pipeline and various components. We take an image and generate regional proposals. These proposals are then warped to a fixed size using a region of interest (RoI) pooling operation, which extracts fixed-length feature vectors from the proposed regions. The R-CNN network comprises a convolutional neural network (CNN) for feature extraction, followed by fully connected layers. The CNN extracts features, and the subsequent layers perform object classification, determining the object’s presence and its class. Additionally, the network incorporates bounding box regression to refine the coordinates of the bounding box around the object.

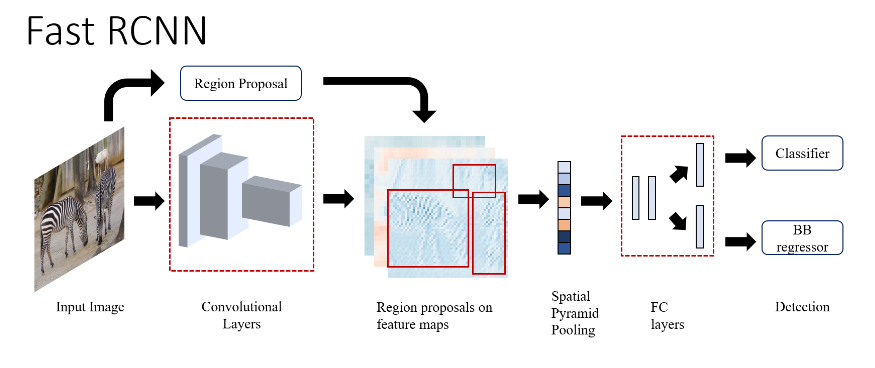
Fast RCNN (2015)
Based on Region Convolutional Neural Network (RCNN), a modified algorithm called Fast R-CNN was developed. It is faster than its predecessor because it does not use whole images to detect objects, but instead utilizes special features that the neural network has identified. These features are much smaller in size compared to the original images. With the help of these features, feature maps are generated, taking into account the resized maps. Next, SPP (Spatial Pyramid Pooling) is applied to extract features from different levels of the feature maps. These features are passed to the fully connected layer, which performs object classification and refinement, as in previous architectures.
Faster RCNN (2015)
Another modification that has significantly accelerated the process is Faster R-CNN. In this algorithm, regional proposals are generated using a neural network. This enables more fine-grained processing, simplifying training and facilitating the application of various optimization techniques to optimize the network for different platforms.
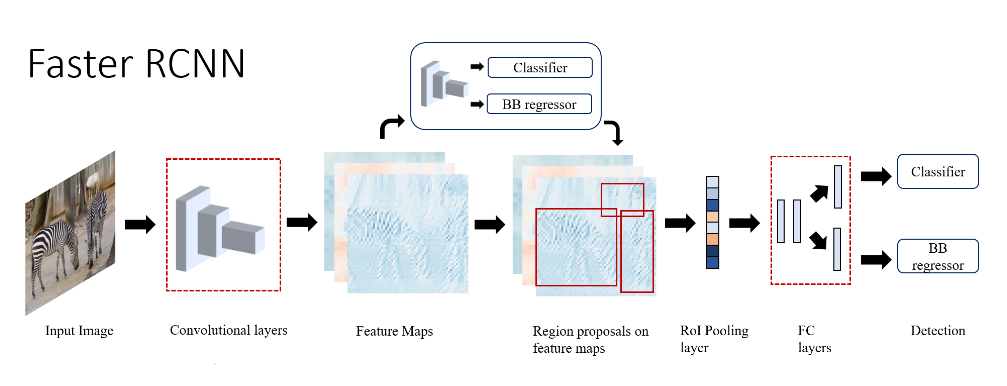
FPN (2017)
The next algorithm we’ll talk about today is Feature Pyramid Networks (FPN), which is a modification of Faster R-CNN. Although it provides more accurate results compared to Faster R-CNN, Feature Pyramid Networks (FPN) maintains a similar processing speed. In FPN, feature maps are not extracted only from the last layer of the network, as it was before, but from different stages of image processing. These features are then aggregated through a top-down pathway and lateral connections using element-wise addition, and based on the resulting feature pyramid, initial suggestions are created for another neural network that performs object classification and detection.

This is an overview of some two-stage object detection algorithms. Each of them has its own advantages and can be used depending on the needs of your project.
Backbones
The development of Object Detection algorithms is an active research area, where much attention is paid to the impact of various architectures, such as backbone, on the accuracy and efficiency of detectors. We will look at the impact of backbone on two-stage detectors and discuss important aspects of this issue.

In order to generate accurate object proposals based on features, it is necessary to have high-quality features that will allow you to find objects in the image. The choice of a suitable backbone architecture has a significant impact on the accuracy of the detector. For example, popular architectures such as MobileNet, Inception, and ResNet exhibit different efficiency and accuracy characteristics.
The accuracy of extractor features can be evaluated by training the backbone on an object detection dataset with ground truth bounding boxes, using a suitable loss function. The head of the architecture is typically modified or augmented with additional layers to enable object detection.
Training the backbone in the Faster R-CNN architecture can be challenging due to its interdependence with other components. In this case, the neural network components, including the backbone, region proposal network, and object detection heads, are trained jointly.
First, the neural network components, including the feature extractor, are trained jointly. The feature extractor is not frozen after feature extraction, and it continues to be fine-tuned alongside other components.
An interesting characteristic of Faster R-CNN is its two-stage learning process, which involves training the region proposal network (RPN) first, followed by the training of object detection heads.
Currently, training one-stage object detection algorithms, such as YOLO (You Only Look Once) or SSD (Single Shot MultiBox Detector), has been greatly simplified as they are trained in one pass, but they still have their own nuances.
One-Stage Detectors
YOLO (2015)
One of the one-stage detectors is YOLO (You Only Look Once). Although a simple diagram below does not fully describe the inner workings of the algorithm, it helps to understand the general concept.
The image is divided into a grid of cells, where the size of the grid is configurable. Each cell contains features used for object detection.
The main idea is that YOLO predicts bounding boxes and class probabilities for multiple objects in each cell, without assuming a maximum of 2 objects in each cell.
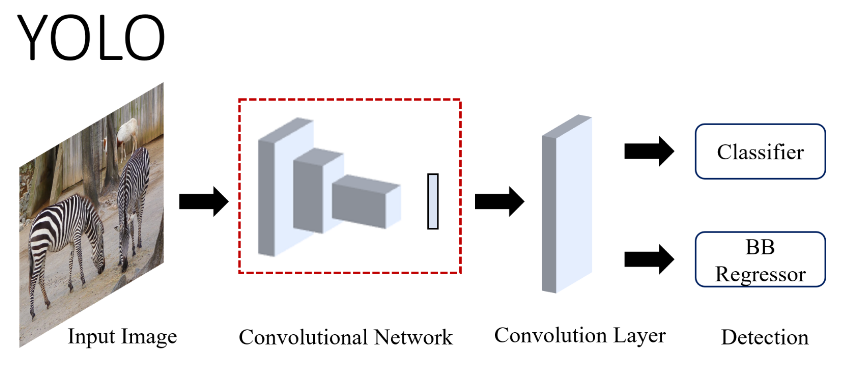
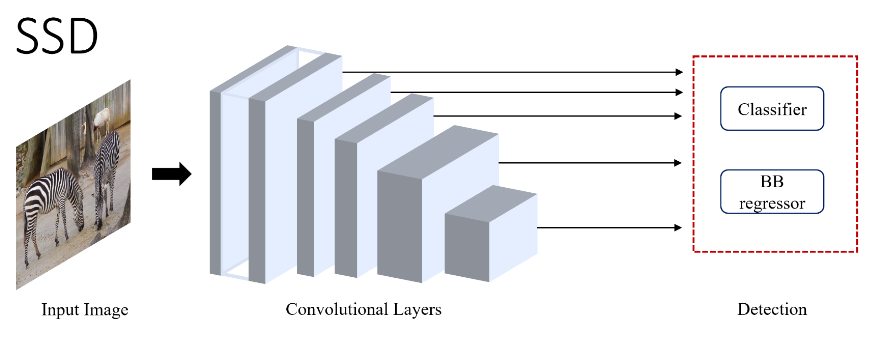
SSD (2015)
Another one-stage detector is the SSD (Single Shot MultiBox Detector), which is a one-stage detector that works by aggregating features from different layers into the final classifier and regressor.
RetinaNet (2017)
RetinaNet is another significant one-stage detector that aggregates information about context and texture features to achieve high accuracy in object localization. It also utilizes a focal loss function and a feature pyramid network.

CenterNet (2019)
The CenterNet architecture, released in 2019, is another one-stage solution worth mentioning.

The original proposal to form such grids has its challenges, especially when working with large satellite images containing, for example, thousands of objects.
Instead of defining a bounding box, CenterNet assigns a center point to each object. This allows for object detection and counting using the center point, in combination with the predicted offsets, to generate a bounding box that encompasses the object.
A significant feature of CenterNet is the use of an Hourglass Backbone, which enables multi-scale information fusion and enhances the model’s ability to capture contextual information.
After the Hourglass Backbone, CenterNet performs keypoint assessment and detection.
Object Detectors by Category
The unified and efficient development of algorithms for object detection is a hot topic in the field of computer vision. Today, there are several variants of object detector algorithms that differ in approach and results. One of them is anchor-based two-stage detectors, which are based on two stages of detection. This method uses anchors to suggest regions, which are then analyzed to identify objects.
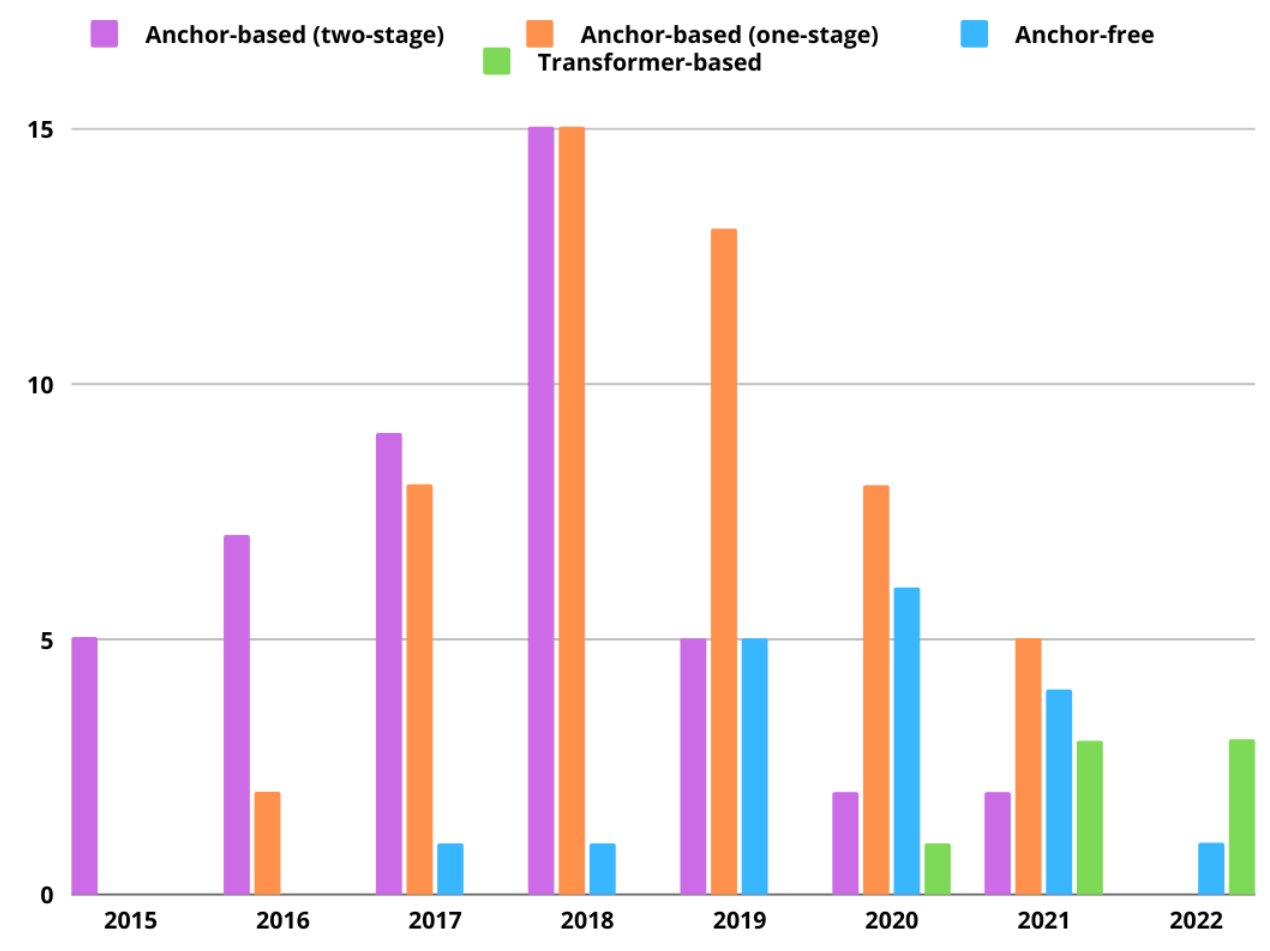
Another option is anchor-free detectors, which offer an anchorless approach to object detection. They use other strategies to identify areas with objects. One of the new and promising areas is the use of transformer-based object detectors. Appeared in 2019, these algorithms based on Visual Transformer are highly accurate. However, they have limitations in performance and computing power due to non-optimization for some platforms. Nevertheless, active research and optimization of these algorithms are already underway.
Transformer-based Detectors
Now I want to draw your attention to the features of transformer-based object detectors. For example, they don’t use Non-Maximum Suppression, a method we’ll talk about later.

A transformer-based object detector is an algorithm that uses the Visual Transformer architecture. Visual Transformer uses a transformer based on the attention mechanism. The attention mechanism was first introduced in the context of the Transformer model in the paper “Attention is All You Need” published by Vaswani et al. in 2017, which revolutionized sequence transduction tasks.
The transformer has repeating blocks and is primarily based on self-attention mechanisms, enabling it to capture dependencies between different positions in the input sequence.
This allows transformers to become a powerful tool in text processing, such as text understanding and text generation. After their success in the field of text processing, transformers are also being used in the field of computer vision, in particular for object detectors.
Visual data is processed by dividing the image into patches and then processing these patches using a transformer. This approach greatly simplifies image processing compared to convolutional networks.
The image patches are flattened and treated as sequences of vectors, which are sequentially processed by the transformer. The output can be utilized for various tasks, including object detection.
For efficient work with vectors, Positional Embedding is used to incorporate positional information into the vectors by adding positional encoding vectors that represent the relative positions of elements.
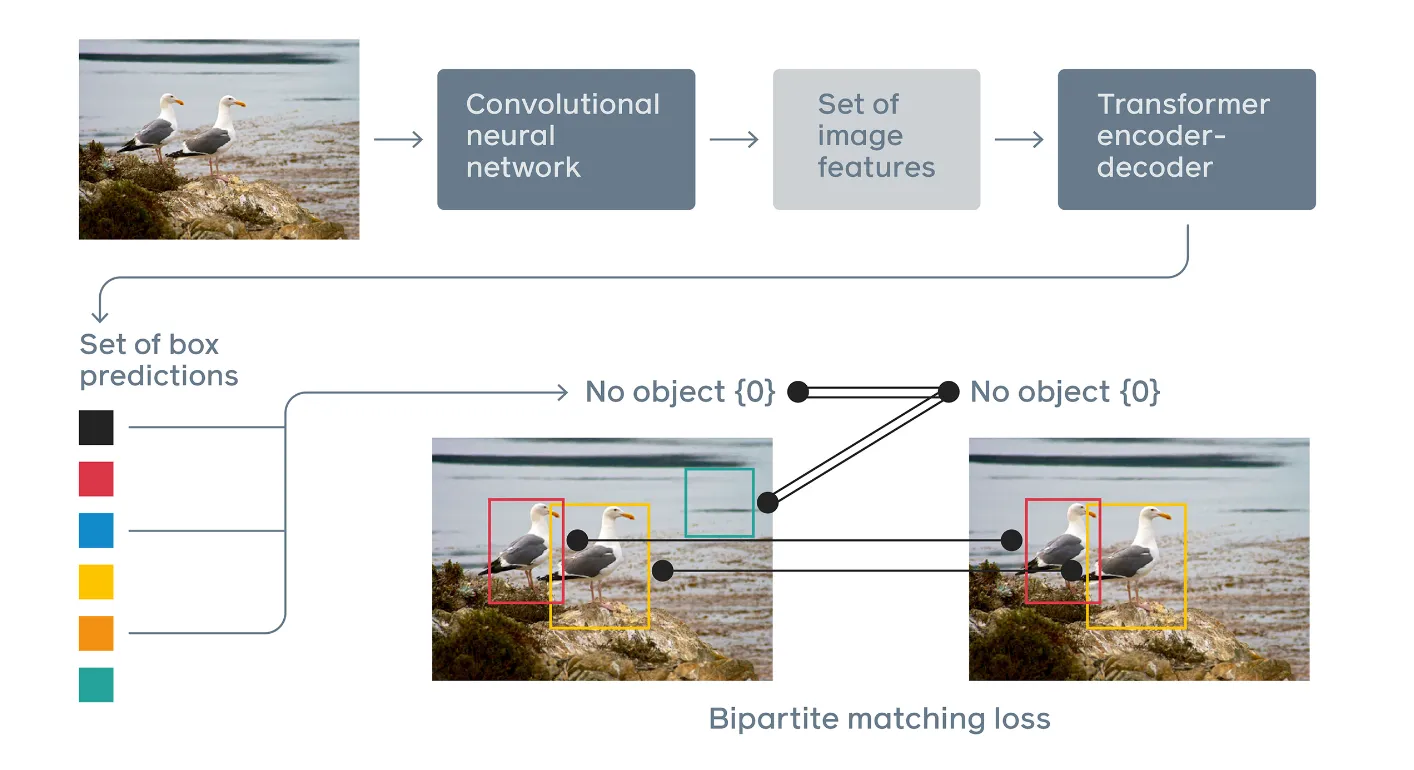
DETR (2020)
DETR is an end-to-end object detection model that directly predicts the bounding boxes and class labels of objects in an image without using Non-Max Suppression. Training such algorithms requires optimizing the model’s parameters using labeled training data and an appropriate loss function.
Swin (2021)
In 2021, the SWIN (Shifted windows) architecture was introduced. The idea behind the SWIN transformer is quite simple. It uses the Visual Transformer technique, which splits the input image into patches, but the SWIN transformer backbone is similar to a Feature Pyramid Network.
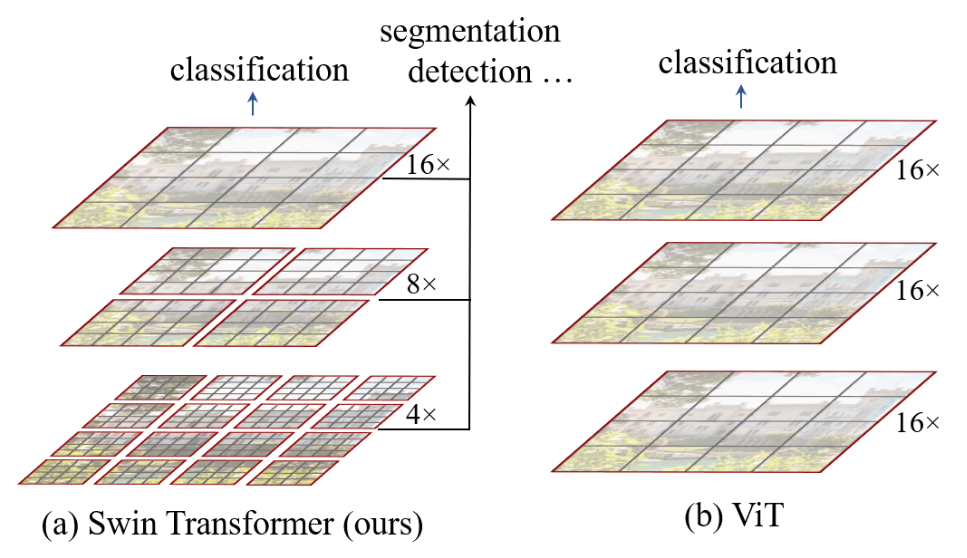
Instead of processing each patch separately, the SWIN transformer divides the input image into a grid of patches, each with a fixed size, and processes them independently before combining them into one large feature vector. This approach enhances the model’s understanding of spatial relationships, improving object localization and segmentation results. The updated second version of the SWIN Transformer demonstrates improved performance in various tasks, such as object detection and instance segmentation.
Non-Max Suppression (NMS)
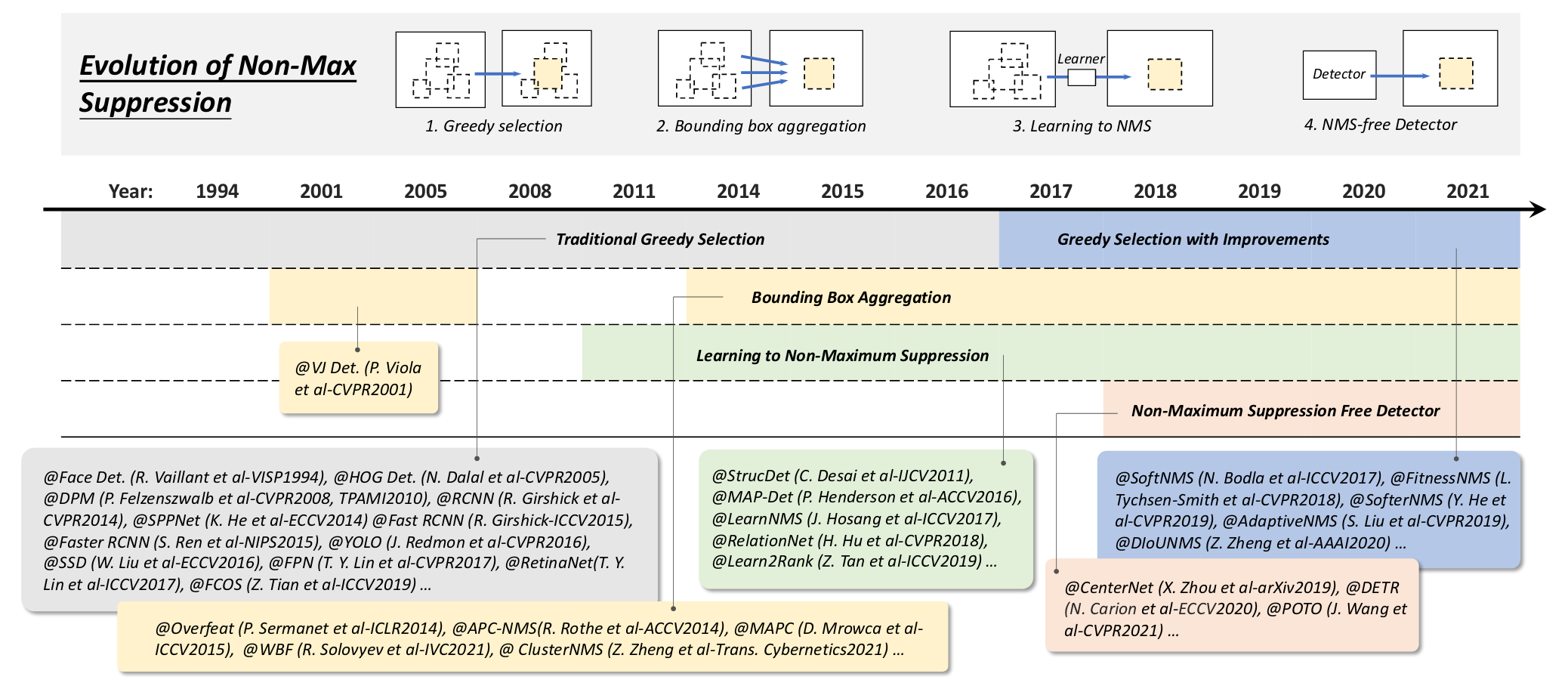
One of the key steps of Object Detection is the Non-Max Suppression (NMS) algorithm, which is used to combine overlapping bounding boxes and obtain one final result.
Let’s imagine a situation where we use the YOLO algorithm for object detection. After processing the image, YOLO returns 4 bounding boxes. However, it turns out that all of these bounding boxes overlap. The question arises when choosing which of these bounding boxes should be considered correct. Each of these bounding boxes can cover only a certain part of the object, but we are interested in the whole object and its exact position.
There were several stages in the development of object detection algorithms. One approach, known as “greedy selection,” was used by Viola Jones and Haar detector but is not specifically part of the Non-Max Suppression (NMS) algorithm. The idea in this approach is to select the largest of all overlapping bounding boxes as the correct result. However, this approach has limitations in terms of detection accuracy.
Another common technique is “bounding box aggregation.” At this stage, all bounding boxes are combined according to specific principles, such as averaging the coordinates of bounding box centers or choosing the maximum or minimum coverage value. The choice of a particular method depends on the task at hand.
In general, the goal is to use all bounding boxes while preserving information by aggregating them. However, it should be borne in mind that this approach also has its drawbacks, especially when using inaccurate bounding boxes that may affect the final result.
Non-Max Suppression (NMS) is performed as a post-processing step after the object detection model generates bounding box predictions. NMS filters out redundant bounding boxes, selecting only the most confident and non-overlapping boxes as the final output.
There are also NMS-free detectors, such as DETR, that do not rely on maximum suppression. These detectors immediately return bounding boxes for each individual object, reducing the need for additional steps after detection. For example, CenterNet is a simple architecture that returns key points, eliminating the need for NMS. Each object is represented by one key point and a distance width that defines a bounding rectangle.
(Zero | One | Few) - Shot Object Detection
In the development of algorithms for object detection, we are slowly moving towards the topic of Few, One, Zero - Shot Object Detection. In this section, we will focus less on technical details and more on a higher level, providing a simple description of the idea of how zero-shot object detection can be performed.
Multimodality

The key concept in this context is multimodality, which means that a neural network can understand several types of data simultaneously. For example, it can be a combination of image and text, image and sound, text and sound, or even image, text, and sound at the same time.

In this approach, we have several input signals, each of which is processed by a corresponding module. In our case, this includes a separate module for text processing, a separate module for image processing, and a separate module for audio processing. These modules form one single neural network that works from start to finish, which is called end-to-end architecture.
Next, fusion modules are used. They may have different names, but they perform the same function - they combine image, text, and audio features and perform certain operations on them. For example, perhaps they look for the most similar image feature vector to a text feature vector. This is similar to the principle of CLIP architecture, which we’ll talk about later.
CLIP (2021)
CLIP adds image-text connection to understand the content of the image.
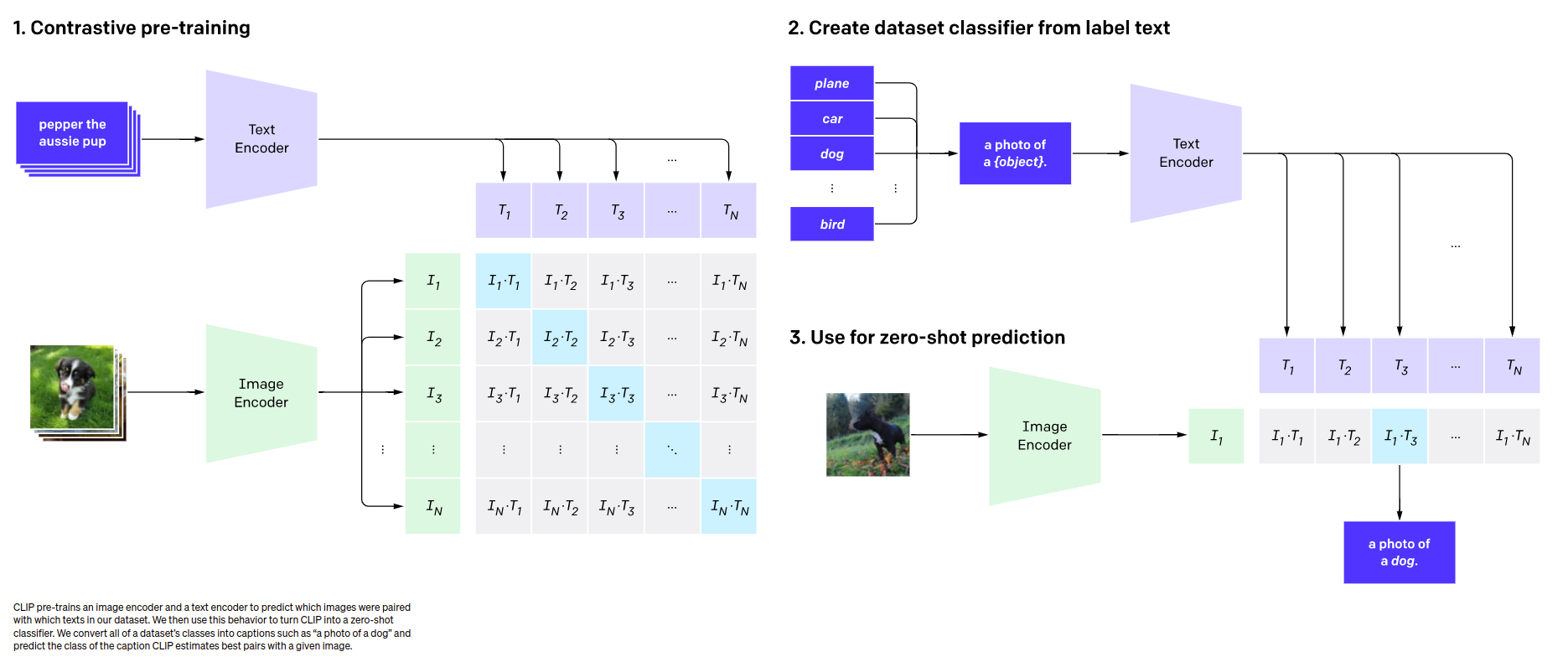
CLIP is a revolutionary development. The main idea behind CLIP is that it creates a connection between images and texts to better understand the context of the image. CLIP uses two models - TextEncoder and ImageEncoder. Each of these models converts data into a vector format.
CLIP is trained on a dataset consisting of text-image pairs, with each pair containing a text description and a corresponding image. During training, the model tries to find the TextEncoder and ImageEncoder parameters so that the vectors obtained for the text and image are similar to each other. The goal is to have the vectors of other text descriptions be different from the target image vector.
When using CLIP for Zero-Shot Object Detection, we can feed an image and a list of words or phrases related to the objects we want to find in the image. For example, if we have an image of a dog, we can use TextEncoder to create a vector with the text “A photo of a dog”. Then we compare this vector with the vectors obtained for each text in the list of words or phrases. The text with the smallest distance to the image vector indicates the object corresponding to the image.
Thus, we can use CLIP to classify objects in images even without separately training the model on a specific dataset with objects. This approach opens up a wide range of possibilities for applying CLIP in the field of Object Detection, where we can utilize the relationships between texts and images to find objects in images.
OWL-ViT (2022)
OWL-ViT adds image-level patches to understand the location of the objects.

In 2022, a new multimodal architecture, OWL-ViT, was introduced for object detection. This network, which is available on the Hugging Face platform, has gained considerable interest in the research and practice community. Let me tell you more about it.
The basic idea is to create embeddings of an image and text, and then compare these embeddings. The image is processed through a Vision Transformer, which generates a set of embeddings. Then, the Vision Transformer applies self-attention and feed-forward networks to these embeddings. Although some of the steps may seem confusing, in practice they help to improve the quality of the model.
Finally, during the training phase, a contrastive loss function is used to encourage corresponding image-textpairs to have similar embeddings, and non-corresponding pairs to have distinct embeddings. The model predicts a bounding box and the probability that a certain text embedding applies to a particular object.
It should be noted that the accuracy of object detection may be limited. The authors of the original model used a process of fine-tuning the pre-trained model with object detection datasets using a bipartite matching loss. This process assists in improving the quality of the detected bounding boxes. More information about this process is shown in the diagrams below.

Now let’s look at an additional feature of this multimodal model. In addition to text, you can use an image as a template. For example, if you have a photo of a butterfly, you can use it as a search query and find similar images. The model is able to analyze both text and images based on common properties.
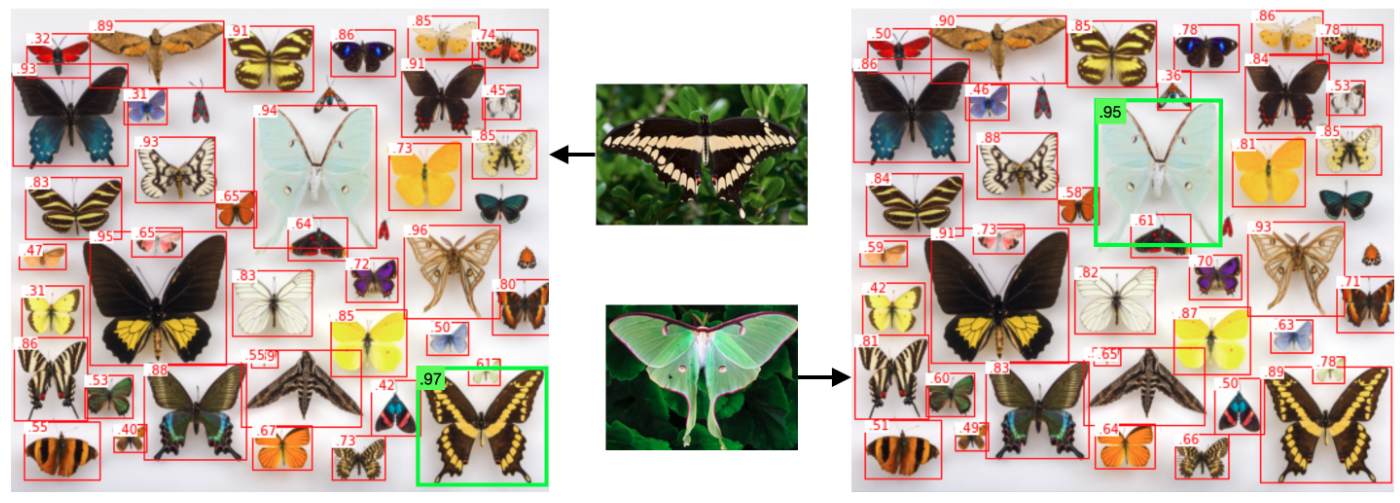
GLIP (2022)
GLIP adds word-level understanding to find the objects by the semantics of the prompt.

GLIP (2022) goes further by providing insight into images to distinguish their semantics. Let’s illustrate this with an example. Suppose we have a sentence about a woman holding a hair dryer and wearing glasses. At the same time, we see an image showing this woman with a hairdryer and glasses. GLIP reformulates object detection as phrase grounding. By accepting both an image and a text prompt as inputs, it can identify entities such as a person, a hairdryer, and others.

This technology offers a new approach to finding objects in an image based on their semantic correspondence with a text prompt. Now, we are not just identifying objects, but also associating parts of the text with components of the image.
Even if you only provide the name of the object, such as “Stingray”, GLIP will be able to find it, but perhaps with a low accuracy. However, if you add a description, such as “flat fish”, it will provide additional context and understanding of what you are looking for. It is important to note that “Prompt Engineering” is of great importance when using ChatGPT and modern Zero-Shot Object Detection methods.

Segment Anything (2023)
Segment Anything (SAM) adds masks to see the pixel-level location of the objects.
This algorithm, introduced in 2023, allows not only to detect objects in images but also to segment them by applying masks at the pixel level.

One of the main features of Segment Anything is its usage of image and prompt encoders to create an overall image embedding, which can be used to segment images based on prompts. These prompts can be spatial, textual, or a combination of both. For instance, you could input “person” as a text prompt, and the algorithm would strive to segment all objects in the image related to a person.
This not only allows you to segment different areas in images, but also to understand the layout and content of the scene. Using the segmentation masks produced by the algorithm, one could potentially perform tasks such as counting the number of instances of an object, given the appropriate post-processing steps.

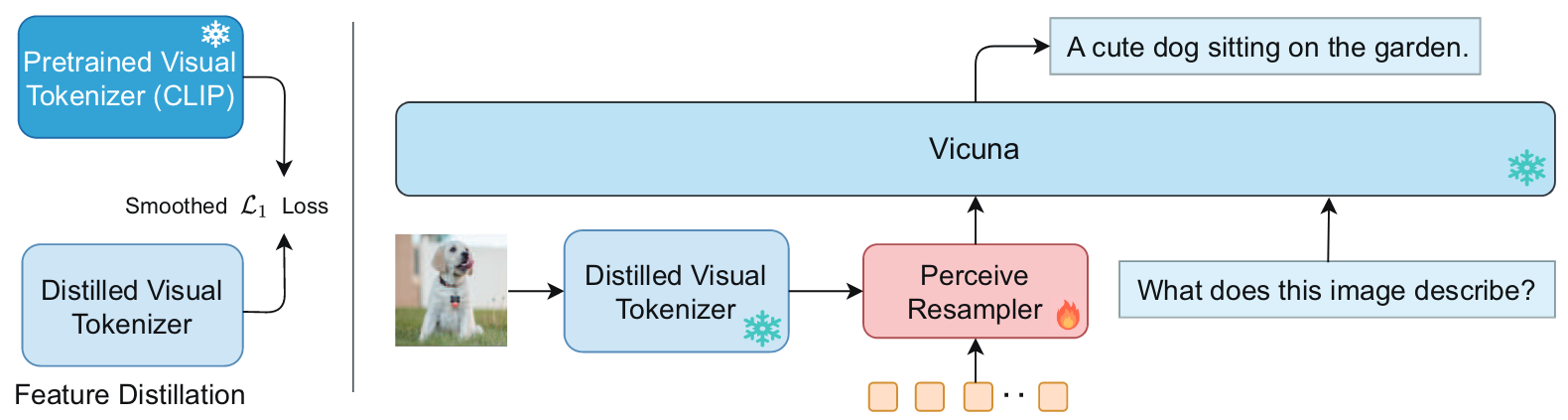
Good Visual Tokenizers (2023)
Good Visual Tokenizers (GVT) is a new Multimodal Large Language Model (MLLM) that involves a visual tokenizer, which has been optimized through proper pre-training methods. This tokenizer aids in understanding both the semantic and fine-grained aspects of visual data.
GVT adds usage of the Large Language Model to investigate the image with the text.

GVT introduces an optimized visual tokenizer within a Large Language Model, enabling a more comprehensive investigation of images along with the associated text. While the application of these algorithms to specific domains such as medical imagery might require additional research, GVT has already demonstrated superior performance on tasks involving visual question answering, image captioning, and fine-grained visual understanding tasks such as object counting and multi-class identification.
Integrating text and images into one model allows you to expand your data understanding and processing capabilities. By using algorithms like the ones above, significant advances can be made in solving a variety of tasks that previously required complex algorithms and large amounts of data.
To sum up Zero-Shot Object Detection:
- CLIP adds image-text connection to understand the content of the image.
- OWL-ViT adds image-level patches to understand the location of the objects.
- GLIP adds word-level understanding to find the objects by the semantics of the prompt.
- SAM adds masks to see the pixel-level location of the objects.
- GVT adds usage of the Large Language Model to investigate the image with the text.
You can learn more about Object Detection Evolution by exploring my presentation below.
Also, check out the online meeting based on this presentation below. Speaking language is Ukrainian.
Conclusion
The evolution of object detection algorithms has been a remarkable journey, from the early days of computer vision to the current state-of-the-art deep learning techniques. Starting with traditional methods like Viola-Jones Detectors and HOG Detectors, we witnessed the transition to more advanced approaches such as RCNN, YOLO, SSD, and CenterNet, which introduced end-to-end architectures for improved adaptability. However, the most groundbreaking leap came with Zero-Shot object detection methods like OWL-ViT, GLIP, Segment Anything, and GVT, enabling us to detect objects in images without the need for extensive neural network training!
Thank you for taking the time to read this article. If you found it informative and engaging, feel free to connect with me through my social media channels.
If you have any questions or feedback, please feel free to leave a comment below or contact me directly via any communication channel in the footer of the website.
I look forward to sharing more insights and knowledge with you in the future!